
Blog’u uzun süredir takip edenler ya da az biraz tanışma fırsatı bulduğum kişiler Managed Extensibility Framework(MEF) ile ilk çıktığı günden beri haşır neşir olduğumu bilir. 🙂 Artık direkt .NET Framework’ün bir parçası olması belki farkındalığını biraz azalttı ama açıkcası .NET ile uygulama geliştirirken belli ihtiyaçları kolayca geliştirmek için güzel bir yapı.
- Plug-in kavramı gibi ek parçalar ile uygulamalara yeni fonksiyonlar eklemek için ortaya çıkan bir yapı.
- WPF, WinForms, ASP.NET gibi farklı uygulama tiplerinde kullanılabilmekte.
- .NET Framework 4.0 ile beraber, .NET Framework’ün içine dahil edildi.
- Uygulamanın bütünlüğünü çok değiştirmeden sadece fonkisyonları kolayca ekleyip, çıkarmak mümkün olabiliyor.
Daha önceleri paylaştığım yazılara da göz atmanızı tavsiye ederim. [MEF Yazıları]
Gelelim bu yazımızın konusuna; .NET Core’da Managed Extensibility Framework(MEF) kullanımı…
MEF, .NET Core’a Microsoft.Composition ile port edildi. Ama ne yazık ki tüm API’ları ile beraber edilmedi. Önemli bir kaç API port edilemese de, MEF’in karakteristik özelliklerini ve temel fonksiyonlarını sorunsuz bir şekilde .NET Core’da kullanabiliyoruz.
Port edilen API’lar sadece System.Composition namespace’indeki API’lar. Dolayısıyla MEF’deki en sevdiğim özelliklerden, kataloglar; AggregateCatalog, ApplicationCatalog, AssemblyCatalog .NET Core tarafında kullanılır durumda değil. Dolayısıyla MEF kullandığınız bir uygulamanızı .NET Core’a port etme çalışması içerisindeyseniz, MEF kısımlarında bir kaç düzenleme yapmanız gerekebilir.
Ayrıca sağlıklı MEF’i sağlıklı kullanmak için Microsoft.Composition 1.0.31 min. versiyon olacak şekilde kullanmanızı tavsiye ederim. Bir kaç sinir bozucu hata giderilmiş durumda. NuGet‘den versiyonları takip edebilirsiniz…
Neyse kafanızı yeteri kadar karıştırdığıma göre örnek kodlara geçelim…
Öncelikle MEF bileşeni olarak “export” etmek istediğimiz sınıflar için .NET Framework’de temel olarak ne yapıyorsak, .NET Core’da da devam.
Önce bir interface oluşturup, bu interface ile sınıfımızı geliştirip, [Export] özelliği ile MEF için dışarıya aktarılacak bir sınıf olduğunu belirtmemiz gerekmekte.
namespace NotifyMe.Common
{
public interface IBaseTemplate
{
string Create(string message, string from, string image);
}
}
//Export edeceğimiz sınıfların ayrı bir assembly'de olması,
//MEF'in genişletilebilir özellikleri sunması açısından doğru olacaktır.
namespace NotifyMe.Templates
{
[Export("ChatMessage",typeof(IBaseTemplate))]
public class ChatMessageBaseTemplate : IBaseTemplate
{
public string Create(string message, string from, string image)
{
//Burada takla atalım, zıplayalım, uçalım...
}
}
}
MEF’in tak-çıkart yaklaşımı ile fonksiyonları kullanma yaklaşımdan dolayı, tüm [Export]’ların ayrı assembly’ler yani ayrı projeler olmasına dikkat edin.
Şimdi de export ettiğimiz bileşenleri ana uygulamamızda nasıl alırız buna bakalım. .NET Core tarafında tüm katalogları kullanamadığımız için ContainerConfiguration sınıfı ile MEF bileşenleri için bir katalog oluşturup, bunun üzerinden bileşenleri alıyoruz.
Aşağıdaki örnek bir web uygulamasından(ASP.NET Core); örnekteki uygulamada root dizininde Plugins diye bir klasör var. Bu klasöre konan *.dll’ler, ana web uygulaması tarafından kontrol edilip yüklenmekte. Daha sonra _templates şeklinde bir liste üzerinden erişilebilir duruma geçiyor.Bu sayede bir ASP.NET Core uygulamasında herhangi bir değişiklik yapmadan sadece belli bir dizine(Plugins) ABC.dll’ini koyup belli fonksiyonları çalıştırmak mümkün. Eğer bu fonksiyonu değiştirmek gerekiyorsa, ana uygulamada bir değişiklik yapmadan ABC.dll’i yerine XYZ.dll’ini koyarak fonksiyonu değiştirmek oldukça kolay.
[ImportMany]
private IEnumerable<IBaseTemplate> _templates { get; set; }
public MessageService(IHostingEnvironment hosting, ILogger<MessageService> logger)
{
_logger = logger;
try
{
var rootPath = hosting.ContentRootPath;
var path = Path.Combine(rootPath, "Plugins");
var assemblies = Directory.GetFiles(path, "*.dll", SearchOption.AllDirectories)
.Select(AssemblyLoadContext.Default.LoadFromAssemblyPath)
.ToList();
var pluginContainer = new ContainerConfiguration().WithAssemblies(assemblies);
using (var container = pluginContainer.CreateContainer())
{
_templates = container.GetExports<IBaseTemplate>("ChatMessage");
}
}
catch (System.IO.DirectoryNotFoundException dnfe)
{
_logger.LogError(dnfe.Message);
}
catch (System.Exception ex)
{
_logger.LogError($"Unable to find message templates. {ex.Message}");
}
}
Hızlıca ve kısa oldu ama .NET Core tarafında da MEF API’larının kullanılabilir olduğunun farkındalığı bir çok ihtiyacınızı çok rahat bir şekilde karşılamanız için yol gösterecektir. Özellikle .NET Core’un “dependency injection” desteği ile MEF’in gücü birleştiği zaman ortaya güzel şeyler çıkıyor.

 Bu senaryoda GitHub’daki
Bu senaryoda GitHub’daki 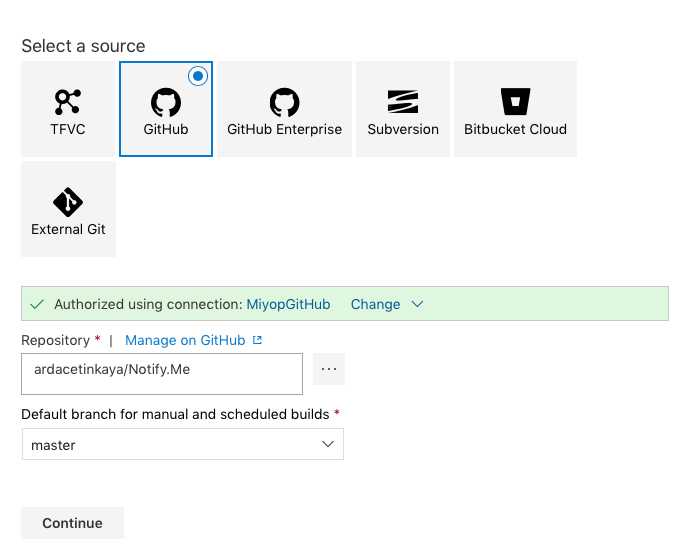

 “Legacy” dediğimiz uygulamalar, sistemler öyle önemli bir değer yaratmışlar ki hala günümüze denk yaşayabilmişlerdir demek ki. 10, 15, 20 yıldır ayakta olan uygulamaları düşünün; ilk kullanıldıkları dönemlerden beri insanlara ve belli iş modellerine o kadar çok değer katıyorlar ki, hala o değeri koruma mücadelesinde içindeler… Biraz daha toparlamak gerekirse “Legacy” diye adlandırdığımız uygulamalar, ne kadar çok negatif bileşenle günümüze gelse de sahip oldukları “değer” çok önemlidir… Ve bu değer uygulamaların en güçlü özelliğidir.
“Legacy” dediğimiz uygulamalar, sistemler öyle önemli bir değer yaratmışlar ki hala günümüze denk yaşayabilmişlerdir demek ki. 10, 15, 20 yıldır ayakta olan uygulamaları düşünün; ilk kullanıldıkları dönemlerden beri insanlara ve belli iş modellerine o kadar çok değer katıyorlar ki, hala o değeri koruma mücadelesinde içindeler… Biraz daha toparlamak gerekirse “Legacy” diye adlandırdığımız uygulamalar, ne kadar çok negatif bileşenle günümüze gelse de sahip oldukları “değer” çok önemlidir… Ve bu değer uygulamaların en güçlü özelliğidir.