.NET dünyasında son 5-6 senedir yaşanan büyük değişikler malum; birden fazla farklı işletim sistemlerinde çalışabilmesi, açık-kaynak yaklaşımlar ile geliştirilmesi, birleşik bir kod tabanı üzerinde sunulan geniş API özellikleri, yazılım geliştirme dünyasında oldukça sıcak konular.
.NET Framework ve .NET Runtime şeklinde hayatımıza giren kavramlardaki değişiklikleri ve yaklaşımları, mevcut durumu ve yol haritasını baz alarak basitçe anla(t)maya, kendimce yorumlamaya çalışacağım. Bazen sorulan sorularda, muhabbetlerde, .NET ile yeni tanışanlarda ya da uzun süredir .NET ile çalışmış ama yenilikleri çok takip edememiş kişilerde kavram karışıklıkları gördüğüm (ya da öyle sandığım) için böyle bir paylaşımda bulunmak istedim. .NET’i daha iyi anlamak geliştirilen çözümlerin kalitesini olumlu yönde de etkileyeceği için umarım faydalı olur.
.NET artık sadece bir Framework değil…
.NET kavramları artık sadece bir “framework” ya da “runtime” yaklaşımı ile yorumlanacak kadar yalın değil. Böyle bir başlıkla yazıyı paylaşmamın sebebi de biraz bu. 😀 Artık .NET kendi içinde bir eko-sistemi olan bir platform. Günümüzün gerektirdiği sistemlerde (web, “cloud”, mobil cihazlar, masaüstü, IoT cihazlar… gibi) çözümler geliştirmek için tercih edilebilecek bir platform. Bu platformun sağladığı API’lar, run-time’lar, framework’ler, araçlar geliştiriciler için kolaylıklar ve imkanlar sağlıyor.
Genel yazılım geliştirme eko-sistemindeki gelişmeler, yazılım geliştirme araçlarının çeşitlenmesi ve yeni fırsatların ortaya çıkması .NET için böyle bir değişikliğin gerekliliğini gösteriyordu zaten. Büyük resme biraz daha yukarıdan bakabilmek ve o şekilde hareket etmek güzel yaklaşım. Bu yüzden Microsoft’un, .NET’e olan bu yeni yaklaşımını bir yazılımcı olarak memnuniyetle karşılıyorum.
Değişim ve adaptasyon
Bulunduğumuz çağda “hızlı” değişim ve “adaptasyon” yazılım çözümlerinin sağlaması gereken en önemli özellik diye düşünüyorum. Bir yazılımın ne kadar uzun süre yaşayabildiğinden çok, yazılımın ne kadar hızlı değişim yaşayabiliyor olması ve yeniliklere adaptasyon sağlaması artık daha önemli. Dolayısıyla değişime ayak uydurmak için .NET platformu da artık daha hızlı değişiyor ve gelişiyor diye düşünüyorum. 2-3 yıl boyunca platform içinde olan bir kavram, 5. yılında belki baştaki desteği sunamayacak, daha farklı ve etken bir alternatifi sunabilecek. Hatta belki de daha da kısa zaman aralıklarında… Alışa gelmiş yazılım geliştirme yaklaşımlara göre belki, “Olur mu ya öyle, niye artık yok. O nasıl kaldırılıyor?” gibi söylemlerde bulunabiliriz belki. Ama artık günümüzde ne kadar geçerli bir bakış açısı bilemiyorum. Geliştirmelerin “topluluk” odaklı ve açık-kaynak odaklı bir şekilde yapılıyor olmasına ek, böyle bir bakış açısından dolayı da .NET’in ara sürümler(preview, release candidate) ile daha sık karşılaşıyoruz, karşılaşacağız. Tabi ki bu ara sürümleri, üretim ortamlarında kullanmak çok sağlıklı değil(?) ama yayınlanacak sürümleri anlamak, gelişmelere adaptasyon sağlamak için bu ara sürümler üzerinde de çalışabilmek önemli.
Microsoft, artık .NET’in çift sayı olan versiyonlarına “Long-term support(LTS)” yani daha uzun süreli destek sağlayacak. Belli versiyonlara olan desteğin daha kısa süreli olacağından, aslında sürekli “güncel” kalabilmeyi desteklemek adına güzel bir hareket.
Uygulama geliştirirken kullandığımız dil dışında, üzerinde çalıştığımız “framework” ya da “kütüphane”API‘larına da hakim olmak, bazı gereksinimleri kolay bir şekilde sunabilmek ya da kullandığımız “framework”‘ü daha etkin kullanabilmek için oldukça önemli diye düşünüyorum. Bu yaklaşımla ASP.NET Core içindeki küçük bir API’dan bahsetmeye çalışacağım; -ki farklı senaryolar için ihtiyaç duyulabilecek güvenli ya da limitli veri modelleri oluşturmak için faydalı olabilir.
Sadece belirli bir süre için geçerli olacak veri modelleri ya da “text” ifadeler zaman zaman ihtiyacımız olan bir yaklaşım olabiliyor. Üyelik işlemlerinde “E-mail onayı” için gönderilen linkler ya da şifre yenilemek için gönderilen linkler sanırım birçok kişiye tanıdık gelecektir. Ya da “soft-OTP”(One-time password) senaryolarında belli bir zaman geçerli olacak kodlar ya da “Bearer” token gibi çeşitli değerler…
Sadece belli zaman geçerli olacak linkler
Açıkçası bu tarz gereksinimler için farklı yöntemler ve yaklaşımlar tabi ki mümkün. Çok derinlere girmeden, .NET platformunda, bu tarz ihtiyaçları nasıl karşılayabiliriz kısaca bundan bahsetmeye çalışacağım.
.NET ve özellikle ASP.NET Core günümüz uygulamalarının güvenlik ihtiyaçlarını karşılayabilmek için birçok API ile bize yol gösteriyor bildiğiniz gibi. Güçlü şifreleme API’ları, HTTPS kavramları, CORS mekanizmaları, CRSF önlemleri, veri koruma, kimlik doğrulama, yetkilendirme, “secret” kullanımı gibi gibi…
Yukarıda az önce bahsetmiş olduğum gereksinim için, “veri koruma” çatısı altında, .NET’de ki ITimeLimitedDataProtector ara yüzüne bakalım. Sadece belli bir süre geçerli olacak veriler ya da ifadeleri bu arayüzün sağladığı metotlar ile karşılayabiliyoruz.
Bu arayüzün metotlarını kullanabilmek için, öncelikle Microsoft.AspNetCore.DataProtection.Extensions kütüphanesine ihtiyacımız var. Genel olarak bu kütüphane .NET içerisinde “veri koruma” özelliklerinin dışarı sunulduğu bir kütüphane.
ITimeLimitedDataProtector arayüzünü kullanabilmek için öncelikle bir tane “DataProtectionProvider” yaratmamız, daha sonra bu “provider” ile de verimizi koruyacak bir koruyucu tanımlamamız gerekmekte.
var timeLimitedDataProtector = DataProtectionProvider.Create("SomeApplication")
.CreateProtector("SomeApplication.TimeLimitedData")
.ToTimeLimitedDataProtector();
Burada metotların parametrelerine baktığınızda göreceğiniz “string” ifadeler önemli; oluşturulan provider ve DataProtector‘lerin bir nevi etiketlenmesi olarak düşünülebilirsiniz. Bu etiketlemeye göre, verilerin güvenliğinin amacı ve kapsamı belirtilmiş oluyor gibi düşünebiliriz. Bu ifadeler veriyi korumak için kullanılacak anahtarların oluşturulmasında kullanılıyor. Böylece, DataProtectionProvider.Create(“abc”) ile oluşturduğunuz bir provider, DataProtectionProvider.Create(“xyz”) şeklinde oluşturulan provider’ın güvenliğini sağladığı ifadelere erişemiyor.
DataProtectionProvider.Create() metodunun parametrelerine baktığınızda veriyi korumak için bazı özellikleri ayarlayabileceğimizi görüyoruz. DirectoryInfo tipinde bir dizin ile veri korumak için kullanılacak anahtarların nerede olacağını ya da X509Certificate2 ile de anahtarların ek olarak bir bir sertifika ile şifreleneceğini belirtebiliyoruz. Bunların çok ayrıntısına girmeyeceğim ama burada belirtmek istediğim, parametreler ile veri koruma şekillerini özelleştirip, koruma yaklaşımlarını değiştirmek mümkün.
Bu şekilde yarattığımız timeLimitedDataProtector değişkeni üzerinden korumak istediğimiz ifadeyi, Protect() metodu ile zaman aralığı belirtip koruyama alıyoruz.
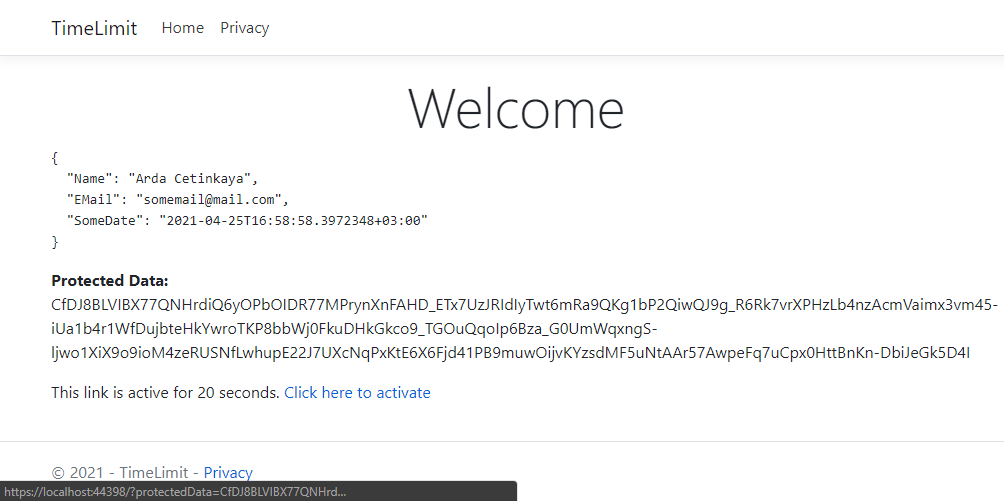
Yukarıdaki ifade ile “Hello World” ifadesini şifreleyip, hash’leyip koruma altına alıyoruz. ProtectedData özelliğimiz 20 saniye geçerli olmak üzere aşağıdakine benzer bir yapıya dönüşüyor.
Protect() metodunun lifetime parametresi ile TimeSpan şeklinde her türlü zamanı belirtebiliyoruz tabi ki de.
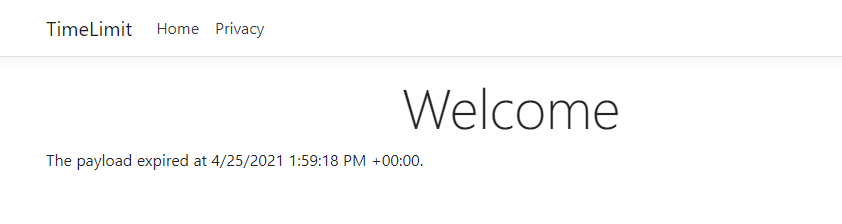
Koruma altına aldığımız; şifrelenmiş ve hash’lenmiş ifadeyi, bu örnekteki gibi 20 saniye içerisinde Unprotect() metodu ile açıp, tekrardan “Hello World” ifadesine ulaşabiliyoruz. Ama 20 saniyeden sonra bu değere ulaşmak mümkün olamıyor ve koruduğumuz veri geçerliliğini kaybediyor.
string data = timeLimitedDataProtector.Unprotect(protectedData);
Bu API ile uzun süre ya da belirsiz süre boyunca veri korunması tavsiye edilmiyor. Bunun sebebi korumaya aldığınızda veriyi şifrelemek ve hash’lemek için kullanılan anahtarların sürekliliğinin sağlanmasının riski. Eğer uzun süre koruma altında saklamanız gereken ifadeler varsa, farklı yöntemler ile ilerlemek mümkün ya da bu API’ın sağladığı interface’ler ile kendi ihtiyaçlarımıza göre farklı geliştirmeler yapılabilir.
Önemli bir nokta da, koruma altına sadece “text” ifadeler alabiliyoruz. Dolayısıyla biraz daha kompleks verileri, “serialize” edip (Ör: JsonSerializer gibi) koruma altına almak mümkün.
Komple resmi daha net görmek için, örnek olması için bir tane ASP.NET Core uygulaması üzerinden Razor sayfa modelinin koduna bakalım.
namespace SomeApplication.Pages
{
using Microsoft.AspNetCore.DataProtection;
using Microsoft.AspNetCore.Mvc.RazorPages;
using Microsoft.Extensions.Logging;
using System;
using System.Text.Json;
public class IndexModel : PageModel
{
private readonly ILogger<IndexModel> _logger;
public string ProtectedData { get; private set; }
public string Data { get; private set; }
public int LifeTime { get; private set; } = 300;
public string Error { get; private set; }
public IndexModel(ILogger<IndexModel> logger)
{
_logger = logger;
}
public void OnGet(string protectedData)
{
var timeLimitedDataProtector = DataProtectionProvider.Create("SomeApplication")
.CreateProtector("SomeApplication.TimeLimitedData")
.ToTimeLimitedDataProtector();
//URL'de ?protecdata= ifadesi boş
if (string.IsNullOrEmpty(protectedData))
{
//Bir tane basit nesne modelimiz olsun
var data = new SomeDataModel
{
Name = "Arda Cetinkaya",
EMail = "somemail@mail.com",
SomeDate = DateTimeOffset.Now
};
//Bu modelimizi JSON olarak "text" şeklinde ifade edelim.
string jsonString = JsonSerializer.Serialize(data, new JsonSerializerOptions
{
WriteIndented = true
});
Data = jsonString;
//Yukarıda LifeTime=20sn. şeklinde tanımladığımız özellikle, modelimizi
//20 saniye geçerli olabilecek bir ifade ile korumaya alalım.
ProtectedData = timeLimitedDataProtector.Protect(plaintext: jsonString
, lifetime: TimeSpan.FromSeconds(LifeTime));
}
else
{
//Sayfaya ?protecdata=a412Fe12dada... şeklinde erişim olduğunda
try
{
//Gelen değerin korumasını kaldırıp, korumaya aldığımız değere ulaşalım
string data = timeLimitedDataProtector.Unprotect(protectedData);
Data = "Data is valid";
}
catch (Exception ex)
{
Error = ex.Message;
}
}
}
}
public class SomeDataModel
{
public string Name { get; set; }
public string EMail { get; set; }
public DateTimeOffset SomeDate { get; set; }
}
}
Yukarıdaki örnekte, bir JSON ifadeyi 20 saniye geçerli olacak bir korumaya alıyoruz ve bunu bir link ile ilişkilendiriyoruz. 20 saniye boyunca link geçerli olacak ve korumaya aldığımız değer geçerli olacaktır. Ama 20 saniye sonunda korumaya aldığımız veri geçerliliğini kaybedecektir.
Bu basit ve hızlı yazı ile uzun bir aradan sonra birşeyler yazmış olmak bana fayda getireceği gibi umarım bu yazı da bazı soru işaretlerini gidermek için sizlere bir kapı açar ve çeşitli çözümlerinizde fayda sağlar. Bir sonraki yazıda görüşmek üzere.
Yazıda küçük bir anektot saklı, bulan olur ve yüzünde küçük bir gülümseme oluşursa ne mutlu 😊
Progressive Web Apps(PWA)’lar gelişen web teknolojileri ve web browser’lar ile değişik deneyimleri ve kazançları kullanıcılara sağlamak adına tercih edilebilecek bir uygulama modeli. PWA’lar için, Web uygulamalarının kullanıcı deneyim avantajları ve masaüstü(desktop) uygulamalarının performans kazanımları, tarayıcı çatısı altında birleşerek, işletim sistemi farklılıklarının da ortadan kalktığı bir uygulama modeli de diyebiliriz.
Biraz daha basite indirgeyerek, tarayıcıların işletim sistemi gibi ele alındığı ve tarayıcı API’larının yeteneklerini kullanarak işletim sistemlerinden bağımsız geliştirilen, tarayıcılara yüklenen web uygulamaları diyebiliriz. Mesela twitter.com, maps.google.com gibi hepimizin oldukça sık kullandığı web siteleri PWA uygulama modeli ile geliştirilen siteler(uygulamalar). Bu sayede Twitter, işletim sistemi özelinde ayrı uygulamalar geliştirmeden, tek bir kod alt yapısı ile masaüstü uygulama(-kısmen) deneyimini sunabiliyor.
PWA özelinde daha fazla ayrıntıya girmeden, Blazor WebAssembly uygulama modeli ile nasıl Progressive Web Apps(PWA) geliştirebiliriz kısaca buna bakmaya çalışacağız. ASP.NET Core çatısı altındaki Blazor uygulama modelinin, WebAssembly yaklaşımı ile bu tarz uygulamalar geliştirmek mümkün. Açıkçası Blazor WebAssembly’nin ne olduğunun çok fazla ayrıntısına girmeyeceğim, ama kısa bir bilgi olması adına; tarayıcıda .NET Runtime’ın WebAssembly üzerinde çalışabilmesini sağlayan bir framework diyebiliriz. JavaScript’e ek olarak C# kodları yazarak da, tarayıcıda çalışan önyüz uygulamalarını Blazor WebAssembly ile geliştirebiliyoruz.
PWA ve Blazor ile ilgili bu kısa girişten sonra küçük bir örnek ile bazı kavramları biraz daha somutlaştırmak istiyorum, hem de daha derinlere dalmak isteyenlere başlangıç noktası ve bazı anahtar kelimeler olur, yani umarım.
Yine belli bir senaryo çatısı altında, aşağıdaki başlıklar ile Blazor’u, Blazor WebAssembly ve PWA yaklaşımlarını biraz anlatmaya çalışacağım. Aslında hepsi ayrı yazı olacak şekilde ele alınacak konular ama bir bütünlük içerisinde, kullanımlarını ve neler yapabilirizi daha iyi anlamak için bir arada paylaşmak istedim. Umarım faydalı olur…
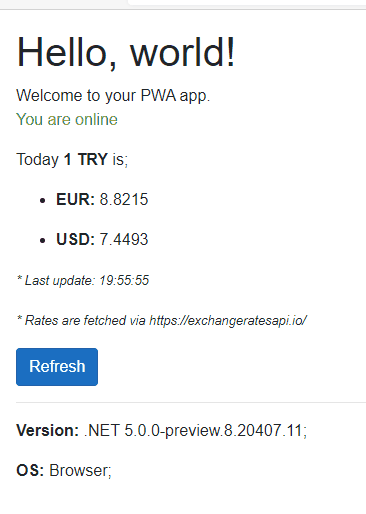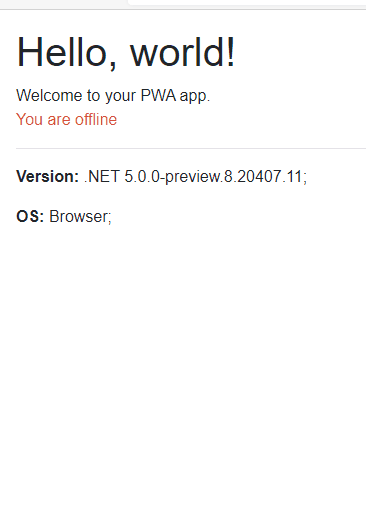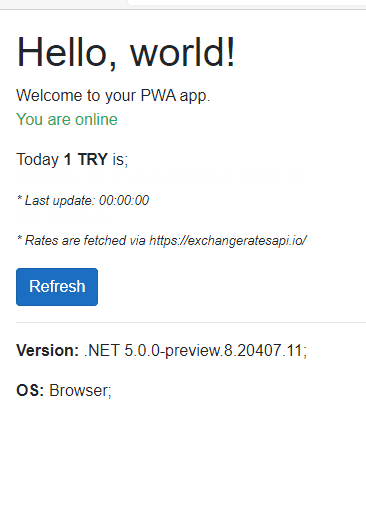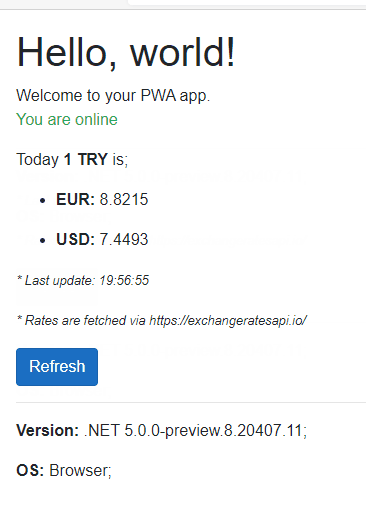
Senaryomuz; bir API kaynağından döviz kurlarının karşılığını alıp gösteren, network durumuna göre offline durumda da çalışabilen basit bir WEB(PWA) uygulaması olsun. (Offff, çok yaratıcıyım… 🤦🏻♂️😀)
IntelliSense özelliği birçok gelişmiş IDE’nin olmazsa olmaz özelliği. –Ki artık öyle kullanım getirileri var ki, IntelliSense olmadan kod yazmak çok hoş karşılanan bir aktivite olmuyor. Üretkenlik, kalite ve hızlı geliştirme ihtiyaçları için yazılımcıların en sevdiği özellik belki de. Visual Studio’nun son sürümü(v16.7) ile birçok yazılımcı için hayat kurtaran bir IntelliSense özelliğine merhaba dedik. Açıkçası basit bir özellik olduğu için onu çok allayıp, pullayıp anlatmayacağım ama böyle bir özelliğin nasıl geliştirildiğini ve biz de benzer şekilde ihtiyaçlar için ne yapabiliriz buna değinmeye çalışacağım. Ama önce Visual Studio’da ne gelmiş bir bakalım…
Visual Studio'nun son sürümü ile DateTime tipindeki değişkenlerin .ToString() şeklinde kullanımında, hangi format neydi derdine son… #visualstudiopic.twitter.com/PwlzWkuVfK
Herkesin bildiği gibi DateTime veri tipini string olarak ifade etmek istediğimizde, çeşitli formatlar ile ifade şeklini ayarlayabiliyoruz. Ama bu formatlardan, hangisinin ne olduğunu hatırlamak bazen direkt mümkün olmuyor, hh/MM/yy mi? Ya da HHHH/MM/Y mi? gibi denemeler/yanılmalar ya da Google’a sormalar her yazılımcının yaptığı aktiviteler.
Hadi DateTime neyse ama bir Regex olayı var ki; kendi adıma aramın pekiyi olduğunu söylemem. Regex ifadeleri yazmak başlı başına ayrı bir mücadele.
Yazılımcıların bu mücadelesini kolaylaştırmak için Visual Studio16.7 sürümü ile IntelliSense özelliklerinde DateTime formatları ve Regex ifadeleri için ipuçları geldi. “Eeee zaten var ki” diyenleri duyar gibi oluyorum. ReSharper gibi eklentiler ile hem cüzdanları hem de Visual Studio’yu yorarak benzer özelliklerden faydalanabiliyorduk.💰🥴
Azure Kubernetes Service(AKS), Kubernetes platformunun Azure üzerindeki yansıması. Malum artık Kubernetes son birkaç yılın oldukça tercih edilen bir platformu. Günümüzün uygulama geliştirme ihtiyaçları ile paralel gelişen, “microservices”, “container” gibi yaklaşımlar ile hızlı değişiklikleri kolay gerçekleştirmeyi sağlayan bir platform olması, günümüzdeki belli kalitedeki çözümlerin temel taşlarından biri olmasını sağladı. O zaman biz de şimdi Azure üzerindeki servisler ile, Kubernetes’den nasıl faydalanabiliriz buna bir bakalım.
Azure Kubernetes Service üzerinde, Azure DevOps ile uygulamalarımızı nasıl dağıtırızı, temel noktaları ile anlatmaya çalışacağım. Hem Kubernetes’i anlamak, hem de Azure servisleri ile tanışmak için güzel bir başlangıç olur umarım. Birkaç anahtar kelime ile de bazı konular için kapı açan bir yazı olur umarım. Yol biraz uzun, çok zaman kaybetmeden başlayalım hemen…
Azure Kubernetes Service dedin de, bu ne alaka…
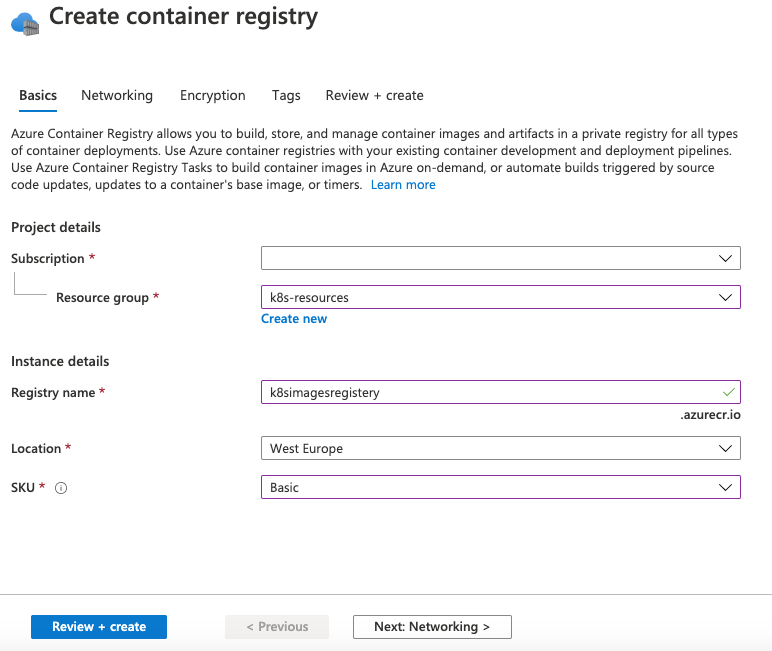
İlk adımımız Azure Kubernetes Service(AKS) tarafında host edilecek, yönetilecek Docker Container’larımızı saklayacağımız Azure Container Registery(ACR)’i oluşturmak. Bu depodan Container’lar alınıp, imaj şeklinde AKS tarafında çalışacak.
ACR’ı oluşturmak portal üzerinden oldukça basit, aşağıdakine benzer şekilde temel bilgiler ile geliştirme ve test amaçlı ACR’ı oluşturabiliriz.
Azure Kubernetes Service’i kuralım bakalım…
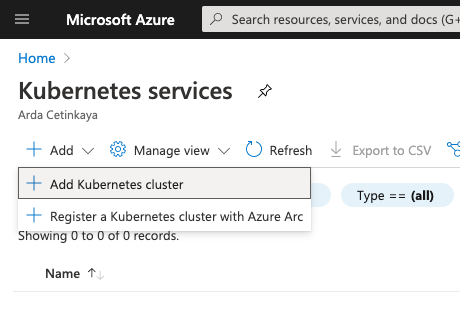
Şimdi sıra geldi Azure Kubernetes Service(AKS) ortamını oluşturmaya. Portal’de tepedeki kutucuğa direkt kubernetes diye yazarak servislere yöneliyoruz. Tabi ki daha henüz hiçbir AKS ortamımız olmadığı için “Add” deyip, “Add Kubernetes Cluster” ekliyoruz.